From the source material
1 / 1
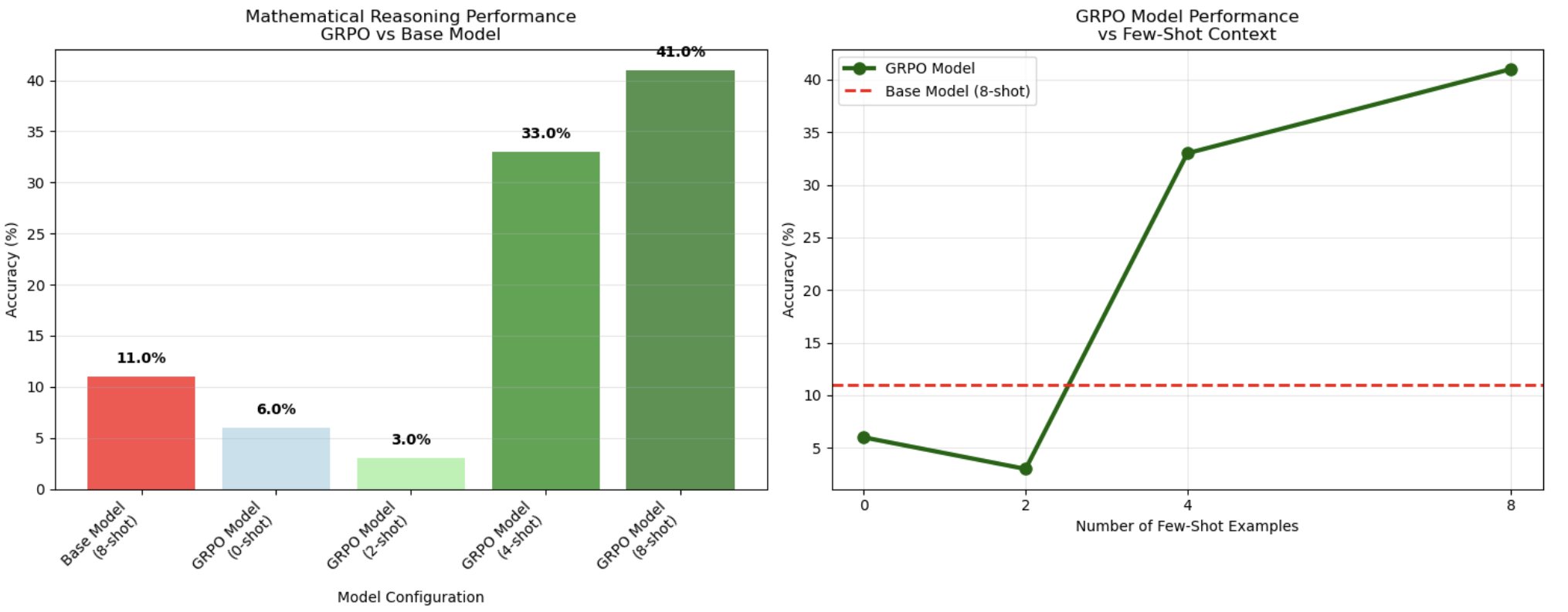
AWS’s example shows accuracy rising from an 11% base model result to 41% for an 8-shot GRPO-trained configuration on a 100-question GSM8K test sample. (Image: AWS)
AWS has published a hands-on guide to reinforcement learning with verifiable rewards, and the useful part is not that SageMaker can run another training job. Of course it can. The useful part is the shape of the reward. In AWS’s tutorial on RLVR with GRPO on SageMaker AI, the team fine-tunes a Qwen2.5-0.5B model on GSM8K math problems using Group Relative Policy Optimization and two programmatic reward functions: one checks whether the answer is formatted correctly, and the other checks whether the final number matches the ground truth. That is small, specific, and blessedly unglamorous. It is also the point.
The real story is that reward design is becoming the product surface. A lot of AI training discourse still talks about reinforcement learning as if the magic lives in a vague cloud of preference, taste, and leaderboard improvement. Verifiable rewards move the center of gravity to something much more concrete: can you write down the thing you want well enough that a program can score it? If the answer is yes, you may have a training signal. If the answer is no, you may have vibes with a GPU budget.
AWS’s example is deliberately narrow. GSM8K is a set of grade-school math word problems with final numerical answers, which makes it unusually reward-friendly. The model gets prompts with few-shot examples, generates multiple completions, and receives up to 0.5 points for using the expected final-answer format plus up to 1.0 point for the correct answer. GRPO then compares outputs within groups and pushes probability toward the better responses. Translation: the model is not being told by a human which answer feels better. It is being trained against a little test harness.
That test harness produced a visible gain, but not a miracle. AWS says the base Qwen2.5-0.5B model reached 11% accuracy on 100 test samples, while the 8-shot GRPO-trained model reached 41%, a 3.7x improvement. The weird detail is more interesting than the headline number: AWS reports that 0-shot and 2-shot GRPO configurations performed worse than the base model, at 6% and 3%, while 4-shot jumped to 33% and 8-shot peaked at 41%. That suggests this setup did not simply inject math skill into a tiny model. It made the trained model more able to exploit a certain kind of prompted reasoning context.
Useful. Also limited. A 100-question test sample is not a new law of model training. Forty-one percent accuracy on grade-school math is still forty-one percent accuracy on grade-school math. And the example requires serious cloud machinery: AWS’s walkthrough uses SageMaker Training Jobs and tells readers they will need access to an ml.p4d.24xlarge training instance for the run. This is a practical tutorial, not a claim that every team should start doing reinforcement learning because a chart turned green.
The practical lesson is where RLVR should and should not go. It fits jobs with objectively checkable outcomes: math answers, structured extraction, code that compiles, unit tests that pass, database queries that return expected rows, transformations that satisfy a schema, symbolic manipulation, policy checks that can be expressed as deterministic rules. It is much less convincing when the target is “sound strategic,” “be medically appropriate,” or “write something executives like” unless those broad goals are broken into verifiable subclaims. Otherwise the reward function becomes a tiny bureaucracy that teaches the model to satisfy paperwork instead of reality.
Code generation is the obvious next stop. If a model can be rewarded for compiling, running without errors, and passing tests, the reward signal is much cleaner than a thumbs-up from someone scanning a diff at 5:47 p.m. But even there, the reward is only as good as the tests. A model that learns to satisfy weak tests is not aligned with your product. It is aligned with your laziness, and it will be very efficient about it. The dry little knife here is that RLVR does not remove specification work. It punishes you for doing specification work badly.
For teams, the workflow should look less like “train a model” and more like “design an evaluation system that happens to train a model later.” Start with one narrow task where correctness is observable. Write reward functions that behave like unit tests, not aspirations. Keep a holdout set that includes ugly cases. Track false positives, not just average reward. Add penalties for malformed, unsafe, or shortcut behavior. Then ask whether the improved model changes the economics of the workflow enough to justify the training run, maintenance, and monitoring. Features are easier to demo than reward drift. That does not make drift less real.
The domain-specific text example is where caution should spike. AWS notes that keyword-based rewards could guide specialized writing toward required terminology. That can be useful for templates and controlled generation. It can also become compliance cosplay if a model learns that mentioning “diagnosis,” “therapy,” and “medication” in the right pattern is the same as producing clinically sound text. Verifiability is not a branding exercise. If the reward checks surface markers while the actual risk lives in reasoning, omissions, or context, the model will learn the surface markers with a straight face.
So this is a standalone Useful Machines story because it points at a practical boundary. Verifiable rewards are not a universal answer to alignment, judgment, or messy human preference. They are a very good answer to a narrower question: how do we improve model behavior when the desired result can be tested? That narrower question matters because many valuable AI workflows are narrower than launch decks admit. They do not need a model to become wise. They need it to produce outputs that pass a real check more often, fail visibly when they do not, and stop treating the reward signal like a slot machine.
AWS’s tutorial is therefore less exciting as an AWS tutorial than as a reminder that the next useful model improvement may come from boring instrumentation. The reward function is where the organization’s definition of “correct” becomes executable. If you can make that definition crisp, RLVR and GRPO give you a way to train against it. If you cannot, the model is not the bottleneck yet. Your spec is. Wonderful news for engineers. Terrible news for anyone hoping reinforcement learning would eliminate the need to say exactly what they mean.
In short
AWS shows how verifiable rewards and GRPO can improve a small model on grade-school math. The useful lesson is not the benchmark bump — it is where reward functions are finally testable enough to trust.